


Contents
The One Instrumental
The original music Easter Egg 'The One' has returned but this time round it is the Instrumental version of the song.
The only other difference with activating the song in this version is that the player will only need to interact with the black telephone once and then the song will play.
If you require a video guide then the video below will show you how to activate the music Easter Egg 'The One Instrumental'.
This video is provided by JokerAlex 21.
Samantha's Hide and Seek: How to Activate Music Easter Egg/Max Ammo 'Samantha's Sorrow'
How to complete the Samantha's Hide and Seek Easter Egg and receive a free Max Ammo and activate the song 'Samantha's Sorrow' by Brian Tuey on Shi No Numa.
The player will need to head over to the 'Fishing Hut' and inside there are 4 metal plates on the walls. The player must shoot with any general weapon at all four plates once, which will then activate a Samantha Laugh sound effect and the Samantha Doll will spawn in the back of the 'Fishing Hut', on the floor on top of some hay.
Once the player has activated the Samantha Doll on the floor they will then need to head over to the bridge just outside the 'Fishing Hut' and the Flogger and shoot the Samantha Dolls that spawn on either side of the bridge 5 times. Once done the player will hear a Samantha Laugh.
Finally the player will need to head back over to the back of the 'Fishing Hut' and interact with the now spinning Samantha Doll. Once done a skeleton arm will pull the doll underground and a free Max Ammo power-up will spawn and the song will begin to play.
If you require a video guide then the video below will show you how to complete the Samantha Hide and Seek Easter Egg and receive a free Max Ammo and activate the song 'Samantha's Sorrow'.
This video is provided by JokerAlex 21.
The Rampage Inducer
The Rampage Inducer can be activated on the map in order to get through the early rounds of the game faster. This can be turned on once the Easter Egg is completed and also turned off at anytime.
Example of the Rampage Inducer inactive.

Example of the Rampage Inducer active.

If you require a video guide then the video below will show you how to activate the Rampage Inducer.
This video is provided by JokerAlex 21.
Free Wunderwaffe DG 2
The Wunderwaffe DG-2 makes a return to Shi No Numa and there is a side Easter Egg to be able to acquire one for free. There are 3 parts that need to be picked up to be able to build the Wunderwaffe DG-2.
The 1st part can be found inside the 'Fishing Hut' over on the 2nd level of the shelf next to the door to the 'Fishing Hut'.
The player will now need to head over to the 'Comms Room Exterior' where they will see, outside the 'Comms Room' hut, in the water there is a green radio tower generator. The player will need to interact with this to place the part that they picked up earlier into it. They will then need to end the current round they are on and in the next round they will need to protect the generator from zombies, boom schreier and sturmkrieger. After a certain amount of time the enemies will all die and the player can now interact with the generator and pick up the charged-up weapon part.
The 2nd part must be picked up and then charged-up. To do this the player will need to pick up 2 parts inside of the 'Comms Room' hut. 1 Part can be found on a shelf inside of a black radio - this is a bulb and the other part can be found on a table in the next room. This is the part needed for a trap.
The player will then need to head to the 'Storage' hut and activate the electric door trap by activating the trap switch behind the perk fountain wall for 1000 points. Once done the trap must kill 3 zombies and as soon as it does the trap switch box will break and open up. The player will now need to place the trap piece they picked up earlier inside the trap box. This will immediately activate the trap once again and the player must get 6 kills with the trap. Once done, if they look at the crafting table for the Wunderwaffe DG-2 they will now see 2 lit up light bulbs.
The 3rd part can only be obtained from round 15 and after. This is because the player needs Zaballa (the mini boss of the map) to spawn in. Once the player has Zaballa they need to head over to 'War Room' which is in the main hut, downstairs near the door that leads to 'Storage' and get Zaballa to use her mine attack on the player next to a tesla coil device. She needs to hit this device 3 times to fully activate the device. Once she does, the player can walk up to the table by the device and pickup the 3rd weapon part - the other light bulb.
Finally the player now needs to head over to the 'Storage' hut and go over to the crafting bench and interact with it, which will now build the Wunderwaffe DG-2.
If you require a video guide then the video below will show you how to build the Free Wunderwaffe DG-2.
This video is provided by JokerAlex 21.
Radios / Ancient Ruins
There are multiple Radios and Ancient Ruin Tablets around the map that contain different parts of the story for Shi No Numa. Once the player walks up and interacts with either a Radio or Ancient Ruin they will be able to listen to some story segments. They can listen to the same Radio or Ancient Ruin as many times as they like in a game. These can only be listened to in game, unlike the Intel in Cold War which could be picked up in game and then listened to on the menu.
If you require a video guide then the video below will show you all locations for all the Radios and Ancient Ruins.
This video is provided by MysteryHQ.
Dark Aether Bunny/Free Points
The Dark Aether Bunny Easter Egg returns again in this map. This Easter Egg will reward the player with many Bonus point power-up pickups, Fire Sale power-up as well as multiple other weapons and grenade types. The Main Easter Egg Quest must be half complete, up to the filling up of the perk fountain with blood step, before this Easter Egg can be started. If you do not know how to do the Main Easter Egg steps up to this point, then use the Main Easter Egg Quest guide below to guide you up to this point.
The player will need to head to the 'Fishing Hut Exterior' and gather up a hoard of zombies in front of the Flogger trap. Once they have a large amount of zombies they will need to run into the 'Flogger Courtyard' and activate the Flogger trap. This will then kill the zombies and fling their bodies over to an empty perk fountain. This will then fill up this perk fountain with zombie blood, which is required to be able to do this Easter Egg, becuase the player must be in zombie blood vision in order to find the Dark Aether Bunny body parts. If the player needs more blood then they can repeat the steps here to refill the perk fountain.
Now the player has zombie blood they need to find 3 different parts for the Dark Aether Bunny while in the zombie blood vision. These can be obtained in any order the player wishes to do them.
If the player heads over to the 'Doctor's Quarter Exterior' they will see, underneath the zipline platform, there is the head part. The player needs to head to the 'Doctor's Quarter Hut' door and activate the trap box, which will bring the zipline platform down to the hut. While it's moving towards the hut, the player will need to get underneath it when its lower down and then interact with it to pick up the Dark Aether Bunny body part.
The player will need to head over to the 'Fishing Hut Exterior' and just outside of the 'Fishing Hut', over in the water next to the fence, they will find the legs for the Dark Aether Bunny.
The player needs to purchase the mystery box at least 3 to 4 times before going into the zombie blood vision. Once done the player should go into the zombie blood vision and then interact with the mystery box once again. Either on that purchase or the next, the box will laugh and move to a new area on the map. While the box is in the laughing animation and the box lifts up into the air, the player will need to quickly interact with the Dark Aether Bunny head part sitting on the pedestal.
As soon as the player has picked up all the Dark Aether Bunny parts there will be multiple Bonus Points power-ups, Fire Sale power-ups, Weapons and grenade type spawns in front of the player to interact with and use within that game they are playing.
If you require a video guide then the video below will show you how to complete the Dark Aether Bunny Easter Egg.
This video is provided by JokerAlex 21.
Creepy Zombie Challenge
There is a mini Easter Egg the player can do on either Shi No Numa or The Archon where the player can find a zombie hidden outside of the map play space. Depending on where the zombie is located will determine what weapon is required for the challenge. There are various challenges for each weapon which involve the floating zombie head from the escort objective. Once the player completes one of these challenges they are rewarded with a load of point drops, max ammo drop and a case with a random level 2 pack a punched weapon.
If you require a video guide then the video below will show you how to complete the Easter Egg and with each of the weapon types for the challenge.
This video is provided by MrDalekJD.
Main Easter Egg Quest
This is the Main Easter Egg Quest of the map that explains the story of Vanguard Zombies going forward into the next map, The Archon. This quest is about trying to recover Saraxi's lost memories.
Step 1
The player must open up to the 'Doctor's Quarters Exterior' and come to the small island with a monolith on it currently covered in red branches. On round 6 the player will want to stand next to this monolith and kill 3 Boom Schreiers next to it, which will remove the red branches from it.
Step 2
The player will now need to find 3 cipher wheel parts around the map. They are located in the 'Doctor's Quarters Hut' in the back room on some boxes, in the 'Dormitory' over on a table next to some beds and the M1 Carbine wall buy and over in the 'Dig Site' on a table opposite the Pack a Punch machine.
The player will now need to find the 3 cipher symbols that they need to input into the cipher wheel. There are 3 pages with these on around the map and these symbols change every game. They are located over in the 'Excavation Room' on a table near the door that leads to 'Storage'. The player will need to either shoot or knife a stack of papers off of the symbol page in order to see the symbol. Another can be found in the 'Comm Room Hut' over on a table next to all the radio equipment. The final symbol can be found over in the 'Dig Site' on the crafting bench, next to the Pack a Punch machine.
Now the player has all the cipher wheel parts and cipher symbols, they will need to head back to the monolith over at the 'Doctor's Quarters Exterior' and walk up to the monolith and interact with it to place in the cipher wheel parts. Once these parts are placed in, the player will need to interact again with the monolith and now they will be placed into a section where they can spin each cipher wheel part around to get the correct symbols. The player cannot be attacked by any enemies while using the cipher wheel's puzzle.
The aim is to get all the correct symbols to the top of the cipher wheels. Down below is a cheat sheet that shows all the possible cipher symbols that are in the game. Use this in order to match the cipher symbol pages which the player found earlier to the ones on the cheat sheet. This can then be used to find the correct symbols for each of the cipher wheels to match to the top of each one. Once all are correct the player will need to lock the code and if done correctly, the cipher wheels will light up red.

Step 3
At this point the player must have the Wunderwaffe DG-2. If they need a guide on how to obtain a free one then the guide above will show how to obtain this.
Once the Wunderwaffe DG-2 is obtained the player will see around the monolith island there are 4 stone pillars. Depending on how many players are in the game will determine how many of these are lit up with a red glow. Once the player is ready to start the next step, they need to interact with the red pillar and if in co-op all players will need to interact with the red pillars at the same time. Once this is done the player will be put into a timed lockdown sequence. During this, the player should stay around the monolith island and round up the zombies. The player will need to kill zombies with a blue orb around them by shooting them with the Wunderwaffe DG-2. Try and kill multiple at once with one shot. If the player completes this in enough time then they will see a blue orb come out of the monolith and this will start a mini story segment. If the player fails this step and does not complete it in enough time then they will need to end the round they are on and then start this step again on the next round.

Step 4
The player will now need to head to the 'Fishing Hut Exterior' just outside the Flinger trap. They will need to train up a large hoard of zombies, then run through into the 'Courtyard' and turn on the Flinger trap. This will then fling the zombies dead bodies over onto the empty perk fountain in the 'Courtyard' which will fill it up with zombie blood.
Once the fountain is full the player will want to save 1 or 2 zombies at the end of the round and then drink from the zombie blood fountain. This will put the player into zombie blood vision. In this vision the player can be hurt by the zombies. The player will then need to look around the main hut until they find a red orb. Once they find the red orb they will need to interact with it and follow it to its intended destination. During this segment the player will be attacked by multiple Boom Schreiers. Once the orb has made it to its location a blue mirror piece will spawn that the player needs to interact with.
In order for the player to obtain the 2nd mirror part they will need to drink from the zombie blood fountain once again. Once this is done they need to head over to this map that can be found in the 'War Room'. On this map will be a red X marked which shows the location for where the mirror part is located. The player will then need to head over to that part of the map. Once there they will then need to look up in the bannister and shoot down the mirror piece so that they can then pick it up.
All possible locations for the mirror piece to spawn in.
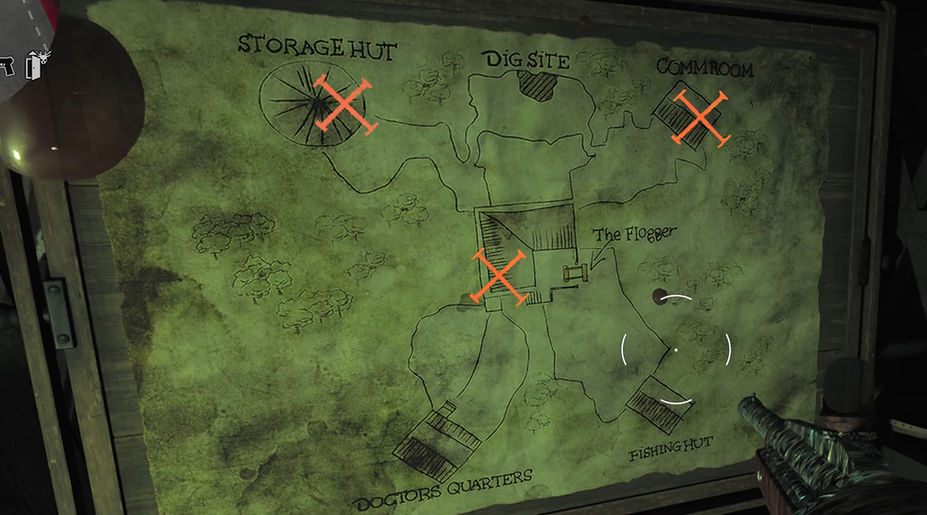
Step 5
Now the player has both mirror parts they will need to head over to the 'Dig Site' and down in the middle they will need to interact with the middle podium and this will place all mirror parts.
The player should now notice that one of the 4 pillars around the area will now have a blue orb above it. If in co-op, the number of players will determine how many of the pillars have blue orbs above them. Once the player interacts with a blue orb it will fly off to a certain area of the map and the player must shoot this orb 3 times for it to then fly back over to the 'Dig Site'. If not done in enough time the player will have to try once again by interacting with the pillar again in the 'Dig Site'.
Below is a great video done by InsaneGamer52 which shows all locations the blue orb can travel to and where to shoot each one.
Step 6
The player will now be heading into the boss fight. So they should make sure they are fully prepared before starting it. To start the boss fight the player will need to interact with the pillar with the blue orb on top of it in the 'Dig Site'. In co-op this will be dependant on how many players are playing. Once done this will start a mini cutscene.
Once the cutscene is finished this will start a 3 phase boss fight. The 1st phase will involve blue orb zombies. The zombies will need to be trained down in the pedestal area and shot at with the DG-2 Wunderwaffe. Try shooting multiple of these blue orb zombies at once.
Once enough are killed, a giant blue orb will spawn around the 'Dig Site'. The player will then need to wait for the boss (Echo) to move into this blue orb and once done, they will want to shoot at the echo's head until eventually it shows invulnerable instead of damage numbers.
Phase 2 is the same as the 1st, only this time the blue orbs will be on the Boom Schreier. Once again kill them with the DG-2 Wunderwaffe and then when enough are killed the giant blue orb will spawn over the 'Dig Site'. Once again repeat what was done the 1st time for attacking the Echo.
Phase 3 is the same as the previous 2 only this time the blue orbs will be on the Stormkrigers. Once again kill them with the DG-2 Wunderwaffe and then when enough are killed the giant blue orb will spawn over the 'Dig Site'. Once again repeat what was done the previous times for attacking the Echo. This time the Echo will die. Once the Echo dies a few cutscenes will play. After this the 2 mirror pieces will attach together and the player can now pick up the mirror and then the Easter Egg quest will be complete and they will be rewarded with multiple pick-ups.
If you require a video guide then the video below will show you how to complete the Main Easter Egg Quest.
This video is provided by JokerAlex 21.
Story Cutscenes
The story cutscenes can be seen here.
This video is provided by JokerAlex 21.